Principal Investigators:
Alan Akbik
Team Members:
Christoph Alt (Postdoctoral researcher)
Jacek Wiland (Doctoral researcher)
SCIoI Project A2
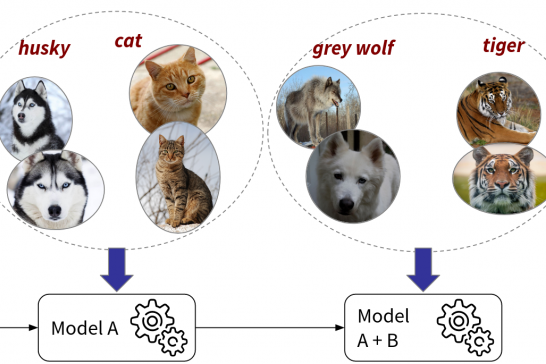
Lifelong learning, also known as continual or incremental learning, aims to develop AI systems that continuously learn to address new tasks from new data while preserving the knowledge acquired from previous tasks. To make this more clear, let’s look at a simple example: assume we want to identify different types of animals. For instance, we initially only observe huskies and cats, so we can only learn a model A based on this partial observation of data. Over time we receive new data for the whole task, for instance grey wolfs and tigers. Based on this newly observed data we then incrementally update the model to also solve task B.
Our scenario assumes that we have an existing model trained on one or multiple tasks and it exhibits certain errors, or groups of errors. For instance, some grey wolves are incorrectly categorized as huskies. Our goal is now to generalize the error correction given the sparse feedback, meaning that we want to correct the systematic error (or group of errors) based on a single example (in the extreme case). To achieve this goal we require a method, or methods, to update the model T based on feedback. For instance, that the image is actually a grey wolf but incorrectly categorized as a husky; and the feedback is potentially very sparse. To summarize, we need to learn how a model encodes task specific knowledge at a more abstract level, so we can very selectively update (or edit) it to correct errors or groups of errors without interfering with existing knowledge.